
در این مطلب قصد داریم تا با الگوریتم های یادگیری تقویتی (Reinforcement Learning) آشنا شویم. همانطور که به صورت جامع در خصوص تعریف یادگیری تقویتی در مطلب “یادگیری تقویتی چیست؟” توضیح داده شده است، یادگیری تقویتی یکی از زیرشاخه های یادگیری ماشین است که در آن یک عامل یادگیرنده در تعامل با محیط سعی میکند به یک سیاست بهینه دست یابد. عامل یادگیرنده با مشاهده وضعیت سیستم (S)، اقدام (A) را انتخاب مینماید. محیط بازخورد این اقدام را در قالب پاداش (R) و حالت بعدی سیستم به عامل بازمیگرداند. عامل مجددا با مشاهده پاداش و حالت سیستم، اقدام بعدی را انتخاب میکند و این فرآیند تا زمان رسیدن به سیاست بهینه ادامه پیدا میکند.
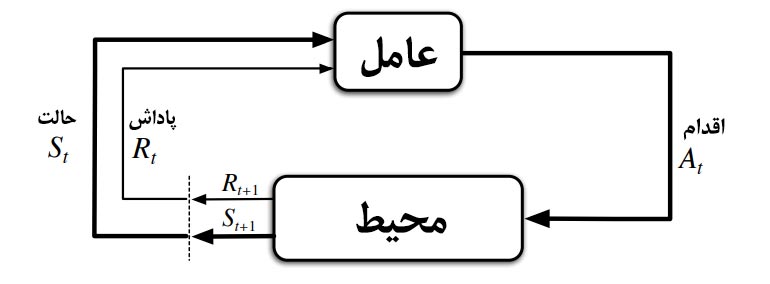
الگوریتمهای مختلفی برای یادگیری تقویتی توسعه داده شده است که هر یک دارای نقاط و ضعف مشخصی است. با ظهور شاخه یادگیری تقویتی عمیق، کاربرد یادگیری تقویتی روزافزون شده است و به موضوعی جذاب چه برای تحقیقات و چه برای کاربرد تبدیل شده است.
انواع الگوریتم های یادگیری تقویتی
در یک دسته بندی کلی میتوان الگوریتم های یادگیری تقویتی را به دو دسته الگوریتم های On-policy و الگوریتم های Off-policy تقسیم بندی نمود:
- الگوریتم های یادگیری تقویتی On-policy: در این الگوریتمها تابع ارزش بر اساس سیاست و اقدام فعلی عامل به روز میشود.
- الگوریتم های یادگیری تقویتی Off-policy: در این الگوریتمها تابع ارزش مستقل از سیاست و اقدام فعلی عامل به روز میشود.
الگوریتم سارسا SARSA یکی از معروفترین الگوریتم های on-policy یادگیری تقویتی است و الگوریتم Q-learning نیز یکی از معروفترین الگوریتم های off-policy یادگیری تقویتی است که در ادامه توضیح داده خواهد شد.
الگوریتم سارسا (SARSA)
الگوریتم سارسا (Sarsa) یک الگوریتم یادگیری تقویتی on-policy است. در این الگوریتم ابتدا عامل یادگیرنده با مشاهده حالت سیستم (S) و بر اساس سیاست مشخص، اقدام (A) را انتخاب میکند. در ادامه بعد از انتخاب اقدام، محیط حالت بعدی سیستم و پاداش را مشخص میکند. عامل با مشاهده وضعیت بعدی سیستم و پاداش دریافتی، مقدار تابع ارزش اقدام (action-value function) را محاسبه و به روز میکند. این روند تا زمانی که مقدار تابع ارزش اقدام به مقدار بهینه آن همگرا شود ادامه خواهد یافت.
جزئیات الگوریتم سارسا (Sarsa) در شکل زیر نشان داده شده است:

همانطور که نشان داده شده است، در مرحله اول میبایست مقادیر اولیه آلفا و اپسیلون و همچنین مقادیر مربوط به ماتریس Q(S,a) هم مشخص شود. سپس یک حالت به صورت تصادفی انتخاب میشود. با سیاست در نظر گرفته شده اقدام در این حالت اتخاذ میشود و پاداش (R) و مقدار بعدی حالت سیستم دریافت میشود. با استفاده از مقادیر مشاهده شده، مقدار Q(s,a) به روزرسانی میشود. همانطور که مشخص است به دلیل on-policy بودن این روش، مقدار ارزش اقدام به صورت مستقیم توسط اقدام و سیاست فعلی به روز میشود.
الگوریتم Q-Learning
الگوریتم یادگیری کیو (یادگیری Q) و یا Q-Learning، یکی از الگوریتم های بسیار معروف از نوع off-policy در حوزه یادگیری تقویتی است. عامل یادگیرنده با الگوریتم Q-Learning، مشابه الگوریتم سارسا، بعد از مشاهده اقدامی (A) را انتخاب میکند. سپس محیط به عامل، حالت بعدی سیستم و پاداش مربوطه ناشی از اقدام اتخاذ شده را بر میگرداند. عامل با مشاهده اطلاعات دریافتی از محیط، اقدام بعدی را انتخاب میکند و این فرآیند تا زمان رسیدن به سیاست بهینه ادامه پیدا میکند. در شکل زیر جزئیات الگوریتم Q-Learning نمایش داده شده است:

همانطور که نشان داده شده است، در مرحله اول میبایست مقادیر اولیه آلفا و اپسیلون و همچنین مقادیر مربوط به ماتریس Q(S,a) هم مشخص شود. سپس یک حالت به صورت تصادفی انتخاب میشود. با سیاست در نظر گرفته شده اقدام در این حالت اتخاذ میشود و پاداش (R) و مقدار بعدی حالت سیستم دریافت میشود. با استفاده از مقادیر مشاهده شده، مقدار Q(s,a) به روزرسانی میشود.
الگوریتم Q-Learning بر خلاف الگوریتم سارسا، یک الگوریتم Off-policy است که این موضوع در فرمول ارائه شده برای به روزرسانی مقدار ارزش – اقدام Q(s,a) مشخص است. مقدار به روزرسانی بر اساس بیشترین مقدار ارزش-اقدام انجام میگیرد (Max Q(s’,a)) و نه بر اساس Q(s’,a).
مقایسه عملکرد الگوریتم Sarsa و الگوریتم Q-Learning
همانطور که ذکر شد الگوریتم سارسا یک الگوریتم on-policy و الگوریتم Q-learning یک الگوریتم off-policy است. بنابراین در رسیدن به سیاست بهینه اختلاف اساسی وجود دارد. حال سوالی که وجود دارد این است که در چه مواقعی از الگوریتم SARSA یا الگوریتم Q-Learning استفاده کنیم؟
در برخی از مقالات اشاره شده است که الگوریتم SARSA سرعت همگرایی بیشتری نسبت به الگوریتم Q-learning دارد. همچنین در الگوریتم سارسا پردازش کمتری نسبت به الگوریتم یادگیری Q احتیاج است. البته بیان شده است که در صورتی که نیاز است تا در زمان کم و با هزینه کمتری سیاست بهینه به دست یابد (مثلاً برنامه ریزی یک ربات در محیط واقعی)، بهتر است از الگوریتم SARSA استفاده شود. در غیر اینصورت و در صورتی که یک مدل شبیه سازی از سیستم وجود دارد و تعداد تکرار بالا هزینه ای را ایجاد نمیکند، الگوریتم Q-learning مناسب تر است.
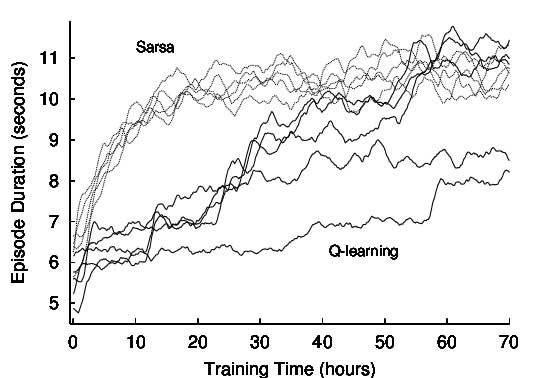
منبع تصویر: سایت Researchhgate
همانطور که در نمودار نیز نشان داده شده است، سرعت همگرایی SARSA بهتر است. ولی در برخی از مقالات بیان شده است که Q-Learning تخمین بهتری از سیاست بهینه به دست میآورد.
چنانچه تمایل به فراگیری یادگیری تقویتی را دارید، پیشنهاد میکنیم در “دوره آموزش یادگیری تقویتی با پایتون” شرکت شبیه پردازان شرکت کنید. جهت آشنایی بیشتر با یادگیری تقویتی مطالب “عملکرد الگوریتمهای یادگیری تقویتی” و “کاربردهای یادگیری تقویتی” را مشاهده کنید.

{kind=link}
{kind=link}