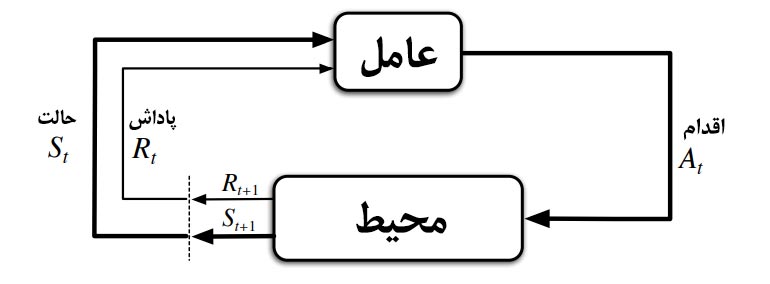
یادگیری تقویتی (Reinforcement Learning یا به اختصار RL) یکی از هیجانانگیزترین و پیشروترین شاخههای هوش مصنوعی است. اگر یادگیری نظارتشده (Supervised Learning) را مانند دانشآموزی بدانیم که با کمک معلم و پاسخهای صحیح درس میآموزد، یادگیری تقویتی مانند کودکی است که از طریق تجربه، آزمون و خطا یاد میگیرد چطور راه برود. ایده اصلی یادگیری تقویتی از روانشناسی رفتارگرا الهام گرفته شده است. در این روش، یک موجود هوشمند که به آن عامل (Agent) میگوییم، در یک محیط (Environment) قرار میگیرد. این عامل با انجام کارهای مختلف و دریافت بازخورد، یاد میگیرد که کدام رفتارها خوب (پاداشدهنده) و کدام رفتارها بد (تنبیهکننده) هستند. هدف نهایی عامل این است که مجموع پاداشهایی را که در طول زمان دریافت میکند، به حداکثر برساند. یادگیری تقویتی از پنج جزء اصلی تشکیل شده است که عبارتند از: عامل یادگیرنده با مشاهده وضعیت سیستم (S)، اقدام (A) را انتخاب مینماید. محیط بازخورد این اقدام را در قالب پاداش (R) و حالت بعدی سیستم به عامل بازمیگرداند. عامل مجددا با مشاهده پاداش و حالت سیستم، اقدام بعدی را انتخاب میکند و این فرآیند تا زمان رسیدن به سیاست بهینه ادامه پیدا میکند. الگوریتمهای مختلفی برای یادگیری تقویتی توسعه داده شده است که هر یک دارای نقاط و ضعف مشخصی است. با ظهور شاخه یادگیری تقویتی عمیق، کاربرد یادگیری تقویتی روزافزون شده است و به موضوعی جذاب چه برای تحقیقات و چه برای کاربرد تبدیل شده است. در یک دسته بندی کلی میتوان الگوریتم های یادگیری تقویتی را به دو دسته الگوریتم های On-policy و الگوریتم های Off-policy تقسیم بندی نمود: الگوریتم سارسا SARSA یکی از معروفترین الگوریتم های on-policy یادگیری تقویتی است و الگوریتم Q-learning نیز یکی از معروفترین الگوریتم های off-policy یادگیری تقویتی است که در ادامه توضیح داده خواهد شد. الگوریتم سارسا (Sarsa) یک الگوریتم یادگیری تقویتی on-policy است. در این الگوریتم ابتدا عامل یادگیرنده با مشاهده حالت سیستم (S) و بر اساس سیاست مشخص، اقدام (A) را انتخاب میکند. در ادامه بعد از انتخاب اقدام، محیط حالت بعدی سیستم و پاداش را مشخص میکند. عامل با مشاهده وضعیت بعدی سیستم و پاداش دریافتی، مقدار تابع ارزش اقدام (action-value function) را محاسبه و به روز میکند. این روند تا زمانی که مقدار تابع ارزش اقدام به مقدار بهینه آن همگرا شود ادامه خواهد یافت. جزئیات الگوریتم سارسا (Sarsa) در شکل زیر نشان داده شده است: همانطور که نشان داده شده است، در مرحله اول میبایست مقادیر اولیه آلفا و اپسیلون و همچنین مقادیر مربوط به ماتریس Q(S,a) هم مشخص شود. سپس یک حالت به صورت تصادفی انتخاب میشود. با سیاست در نظر گرفته شده اقدام در این حالت اتخاذ میشود و پاداش (R) و مقدار بعدی حالت سیستم دریافت میشود. با استفاده از مقادیر مشاهده شده، مقدار Q(s,a) به روزرسانی میشود. همانطور که مشخص است به دلیل on-policy بودن این روش، مقدار ارزش اقدام به صورت مستقیم توسط اقدام و سیاست فعلی به روز میشود. الگوریتم یادگیری کیو (یادگیری Q) و یا Q-Learning، یکی از الگوریتم های بسیار معروف از نوع off-policy در حوزه یادگیری تقویتی است. عامل یادگیرنده با الگوریتم Q-Learning، مشابه الگوریتم سارسا، بعد از مشاهده اقدامی (A) را انتخاب میکند. سپس محیط به عامل، حالت بعدی سیستم و پاداش مربوطه ناشی از اقدام اتخاذ شده را بر میگرداند. عامل با مشاهده اطلاعات دریافتی از محیط، اقدام بعدی را انتخاب میکند و این فرآیند تا زمان رسیدن به سیاست بهینه ادامه پیدا میکند. در شکل زیر جزئیات الگوریتم Q-Learning نمایش داده شده است: همانطور که نشان داده شده است، در مرحله اول میبایست مقادیر اولیه آلفا و اپسیلون و همچنین مقادیر مربوط به ماتریس Q(S,a) هم مشخص شود. سپس یک حالت به صورت تصادفی انتخاب میشود. با سیاست در نظر گرفته شده اقدام در این حالت اتخاذ میشود و پاداش (R) و مقدار بعدی حالت سیستم دریافت میشود. با استفاده از مقادیر مشاهده شده، مقدار Q(s,a) به روزرسانی میشود. الگوریتم Q-Learning بر خلاف الگوریتم سارسا، یک الگوریتم Off-policy است که این موضوع در فرمول ارائه شده برای به روزرسانی مقدار ارزش – اقدام Q(s,a) مشخص است. مقدار به روزرسانی بر اساس بیشترین مقدار ارزش-اقدام انجام میگیرد (Max Q(s’,a)) و نه بر اساس Q(s’,a). همانطور که ذکر شد الگوریتم سارسا یک الگوریتم on-policy و الگوریتم Q-learning یک الگوریتم off-policy است. بنابراین در رسیدن به سیاست بهینه اختلاف اساسی وجود دارد. حال سوالی که وجود دارد این است که در چه مواقعی از الگوریتم SARSA یا الگوریتم Q-Learning استفاده کنیم؟ در برخی از مقالات اشاره شده است که الگوریتم SARSA سرعت همگرایی بیشتری نسبت به الگوریتم Q-learning دارد. همچنین در الگوریتم سارسا پردازش کمتری نسبت به الگوریتم یادگیری Q احتیاج است. البته بیان شده است که در صورتی که نیاز است تا در زمان کم و با هزینه کمتری سیاست بهینه به دست یابد (مثلاً برنامه ریزی یک ربات در محیط واقعی)، بهتر است از الگوریتم SARSA استفاده شود. در غیر اینصورت و در صورتی که یک مدل شبیه سازی از سیستم وجود دارد و تعداد تکرار بالا هزینه ای را ایجاد نمیکند، الگوریتم Q-learning مناسب تر است. منبع تصویر: سایت Researchhgate همانطور که در نمودار نیز نشان داده شده است، سرعت همگرایی SARSA بهتر است. ولی در برخی از مقالات بیان شده است که Q-Learning تخمین بهتری از سیاست بهینه به دست میآورد. یادگیری تقویتی عمیق (Deep Reinforcement Learning یا به اختصار DRL) جهشی بزرگ در دنیای هوش مصنوعی است که از ترکیب دو حوزه قدرتمند به وجود آمده است: یادگیری تقویتی (RL) و یادگیری عمیق (Deep Learning). در یادگیری تقویتی کلاسیک، ما معمولاً از جداول (مانند Q-Table) برای ذخیره ارزشِ هر اقدام در هر وضعیت استفاده میکنیم. اما تصور کنید در یک بازی ویدئویی با میلیونها پیکسل، یا در دنیای واقعی با بینهایت حالت مختلف روبرو هستیم؛ در این صورت: در اینجا شبکههای عصبی عمیق وارد میشوند. آنها به جای ذخیره تکتک وضعیتها، یاد میگیرند که وضعیتها را تعمیم دهند. یعنی با دیدن یک صحنه، شباهتهای آن را با تجربیات قبلی درک کرده و بهترین تصمیم را تخمین میزنند. در یادگیری تقویتی عمیق بر خلاف روش کلاسیک یادگیری تقویتی، برای مشاهده ارزش هر وضعیت، به محاسبات انجام شده در جدول حاقظه عامل مراجعه نمیشود. در این روش یک شبکه عصبی وجود دارد که ورودی آن وضعیت (State) و خروجی آن یکی از موارد زیر است: چهار مورد از تاثیرگذارترین الگوریتمهای یادگیری تقویتی عمیق (DQN) در زیر اشاره شده است: DQN (Deep Q-Network): اولین موفقیت بزرگ که توسط DeepMind معرفی شد. این الگوریتم توانست بازیهای آتاری را صرفاً با نگاه کردن به پیکسلهای صفحه، بهتر از انسان بازی کند. Policy Gradient: الگوریتمهایی که به جای تخمین پاداش، مستقیماً روی بهینه کردن رفتار (Policy) تمرکز میکنند. Actor-Critic (A2C/A3C/SAC): ترکیبی هوشمندانه که در آن یک شبکه (Actor) اقدام را انتخاب میکند و شبکه دیگر (Critic) آن اقدام را نقد کرده و امتیاز میدهد. PPO (Proximal Policy Optimization): یکی از محبوبترین الگوریتمها که توسط OpenAI توسعه یافته و به دلیل پایداری بالا، در آموزش رباتها و حتی مدلهای زبانی (مثل ChatGPT) استفاده میشود. نفوذ بکارگیری الگوریتم های یادگیری تقویتی به خصوص بعد از ظهور یادگیری تقویتی عمیق، روندی روزافزون داشته است و به ندرت میتوان حوزهای شناسایی نمود که این پیاده سازی این الگوریتم ها در آنها یا به صورت عملی و یا به صورت تحقیقاتی انجام نشده باشد. به صورت کلی چند دسته کلی برای کاربردهای یادگیری تقویتی می توان ارایه نمود که توضیحات مربوط با کلیک کردن بر روی هر کدام قابل مشاهده است. بازیها و شبیهسازی (Gaming & Simulation) رباتیک و سیستمهای خودگردان (Robotics & Autonomous Systems) هوشمندسازی صنعتی، زنجیره تأمین و لجستیک (Smart Operations, Supply Chain & Logistics) اقتصاد، بازارهای مالی و تجارت (Finance & Trading) مراقبتهای بهداشتی و پزشکی (Healthcare & Medicine) سیستمهای توصیهگر و شخصیسازی (Recommender Systems & Personalization) انرژی و مدیریت منابع (Energy & Resource Management) پردازش زبان طبیعی و مدلهای زبانی (NLP & Large Language Models)یادگیری تقویتی (Reinforcement Learning) چیست؟
اجزای اصلی یادگیری تقویتی و فرآیند آن
الگوریتمهای یادگیری تقویتی
الگوریتم سارسا (SARSA)

الگوریتم Q-Learning
مقایسه عملکرد الگوریتم Sarsa و الگوریتم Q-Learning
یادگیری تقویتی عمیق (Deep Reinforcement Learning)
الگوریتم های یادگیری تقویتی عمیق
جمع بندی قابلیتها و مقایسه سریع الگوریتم های ذکر شده در جدول زیر ارایه شده است.
الگوریتم
دسته بندی نقطه قوت مورد استفاده DQN Value-based ساده و کلاسیک محیطهای با دکمههای محدود (بازیها) PPO Policy-based پایداری بسیار بالا رباتیک و مدلهای زبانی (RLHF) A3C Actor-Critic سرعت بالا (موازیسازی) شبیهسازیهای سنگین SAC Actor-Critic جستوجوی هوشمندانه کنترل دقیق موتورها و رباتیک کاربردهای یادگیری تقویتی
یادگیری تقویتی (RL) چیست؟ (الگوریتم ها، کاربردها، نرم افزارها)
folder_openیادگیری تقویتی
commentبدون دیدگاه

 چیست؟ (الگوریتم ها، کاربردها، نرم افزارها)){kind=link}
 چیست؟ (الگوریتم ها، کاربردها، نرم افزارها)&description=&image=https://www.shabihpardazan.com/wp-content/uploads/2022/02/RlTraining.jpg){kind=link}
Tags: off-policy, on-policy, q-learning, sarsa, الگوریتم Q-learning, الگوریتم SARSA, الگوریتم های یادگیری تقویتی, الگوریتم یادگیری تقویتی, سارسا, مقایسه الگوریتم یادگیری تقویتی, یادگیری Q, یادگیری تقویتی